如何让AI知道私人数据–RAG
准备外部数据
用户提问后搜索
询问模型
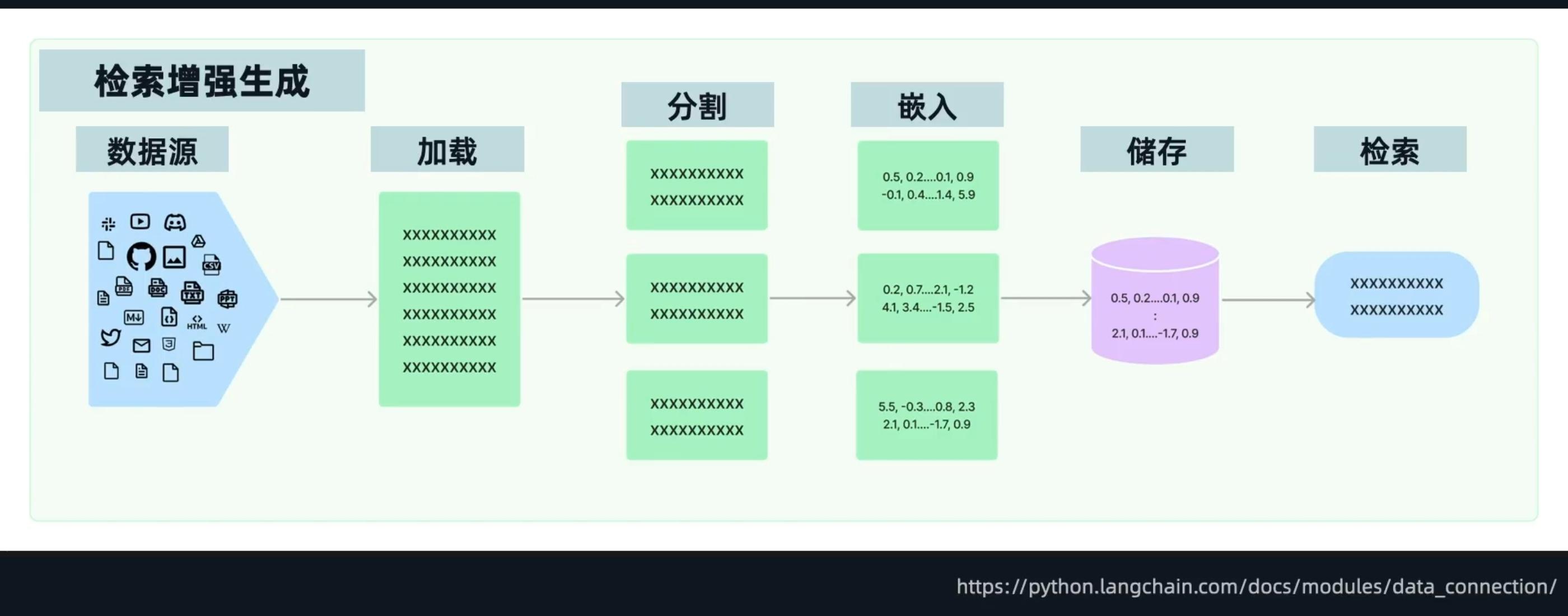
外部文档读取
TXT加载示例
import os from langchain_community.document_loaders import TextLoader from langchain.memory import ConversationBufferMemory from langchain.chat_models import ChatOpenAI from langchain.chains import ConversationChain # 设置你的OpenAI API密钥 os.environ["OPENAI_API_KEY"] = "your_openai_api_key_here" # 加载文本文件 loader = TextLoader("example.txt") documents = loader.load() # 将文档内容合并成一个字符串 document_content = "\n".join([doc.page_content for doc in documents]) # 创建一个ConversationBufferMemory实例 memory = ConversationBufferMemory() # 初始化ChatOpenAI模型 chat_model = ChatOpenAI(model_name="gpt-3.5-turbo") # 创建一个ConversationChain实例 conversation_chain = ConversationChain( llm=chat_model, memory=memory, verbose=True ) # 示例对话 user_input_1 = f"请阅读以下文本并回答问题:\n{document_content}\n问题:这段文本的第一句话是什么?" response_1 = conversation_chain.run(user_input_1) print(f"AI: {response_1}") user_input_2 = "请继续回答:这段文本的第二句话是什么?" response_2 = conversation_chain.run(user_input_2) print(f"AI: {response_2}") user_input_3 = "请总结这段文本的主要内容。" response_3 = conversation_chain.run(user_input_3) print(f"AI: {response_3}")PDF加载示例
# 安装必要的库 # pip install langchain-community openai pydantic ipython python-dotenv from langchain_community.document_loaders import PyPDFLoader from langchain_openai import ChatOpenAI from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate from IPython.display import display, display_markdown from pydantic import SecretStr from langchain.schema.messages import (SystemMessage, HumanMessage) from dotenv import load_dotenv import os # 加载 .env 文件 load_dotenv() # 创建聊天模型实例 model = ChatOpenAI( model="gpt-3.5-turbo", api_key=SecretStr(os.getenv("OPENAI_API_KEY")), # 确保使用正确的 API 密钥变量名 temperature=0.3, frequency_penalty=1.5 ) # 定义示例提示模板 example_prompt = ChatPromptTemplate.from_messages( [ ("human", "总结以下文档内容:\n{document_content}"), ("ai", "##文档摘要\n{summary}") ] ) # 定义示例数据 examples = [ { "document_content": "这是一个示例文档。它包含一些基本信息。", "summary": "这是一个包含基本信息的示例文档。" }, { "document_content": "这是另一个示例文档。它提供了详细的描述。", "summary": "这是一个提供了详细描述的示例文档。" } ] # 定义少样本提示模板 few_shot_template = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) # 定义最终提示模板 final_prompt_template = ChatPromptTemplate.from_messages( [ few_shot_template, ("human", "{input}"), ] ) # 加载 PDF 文件 pdf_loader = PyPDFLoader("example.pdf") # 确保 example.pdf 存在于当前目录中 documents = pdf_loader.load_and_split() # 假设我们只使用第一个文档的内容 document_content = documents[0].page_content # 生成最终提示 final_prompt = final_prompt_template.invoke( { "input": f"总结以下文档内容:\n{document_content}" } ) final_prompt.to_messages() # 调用模型并显示结果 response = model.invoke( final_prompt ) display_markdown(response.content, raw=True)在线资源加载示例
# 安装必要的库 # pip install langchain_community openai pydantic ipython from langchain_community.document_loaders import WikipediaLoader from langchain_openai import ChatOpenAI from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate from IPython.display import display, display_markdown from pydantic import SecretStr from langchain.schema.messages import (SystemMessage, HumanMessage) from dotenv import load_dotenv import os # 加载 .env 文件 load_dotenv() # 创建聊天模型实例 model = ChatOpenAI( model="gpt-3.5-turbo", api_key=SecretStr(os.getenv("OPENAI_API_KEY")), # 确保使用正确的 API 密钥变量名 temperature=0.3, frequency_penalty=1.5 ) # 定义示例提示模板 example_prompt = ChatPromptTemplate.from_messages( [ ("human", "总结以下文档内容:\n{document_content}"), ("ai", "##文档摘要\n{summary}") ] ) # 定义示例数据 examples = [ { "document_content": "这是一个示例文档。它包含一些基本信息。", "summary": "这是一个包含基本信息的示例文档。" }, { "document_content": "这是另一个示例文档。它提供了详细的描述。", "summary": "这是一个提供了详细描述的示例文档。" } ] # 定义少样本提示模板 few_shot_template = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) # 定义最终提示模板 final_prompt_template = ChatPromptTemplate.from_messages( [ few_shot_template, ("human", "{input}"), ] ) # 加载 Wikipedia 页面 wikipedia_loader = WikipediaLoader(query="LangChain", lang="zh") documents = wikipedia_loader.load() # 假设我们只使用第一个文档的内容 document_content = documents[0].page_content # 生成最终提示 final_prompt = final_prompt_template.invoke( { "input": f"总结以下文档内容:\n{document_content}" } ) final_prompt.to_messages() # 调用模型并显示结果 response = model.invoke( final_prompt ) display_markdown(response.content, raw=True)
文本块应用
- TextLoader example
from langchain_community.document_loaders import TextLoader from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough, RunnableParallel from langchain_core.output_parsers import StrOutputParser from pydantic import SecretStr import os from dotenv import load_dotenv # 加载 .env 文件 load_dotenv() # 初始化模型 model = ChatOpenAI( model="qwen-turbo", api_key=SecretStr(os.getenv("DASHSCOPE_API_KEY") or ""), base_url=os.getenv("BASE_URL"), temperature=0.3, frequency_penalty=1.5 ) # 自定义TextLoader示例 loader = TextLoader("example.txt", encoding="utf-8") documents = loader.load() # 提取文档内容 document_content = documents[0].page_content if documents else "" # 构建Prompt模板 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个擅长总结内容的助手。"), ("human", "请总结以下文本内容:\n{content}") ]) # 使用LCEL构建链式调用 chain = ( RunnableParallel(content=RunnablePassthrough()) # 将输入直接传递给prompt中的{content} | prompt | model | StrOutputParser() ) # 执行并输出结果 summary = chain.invoke(document_content) print(summary)
文本向量化–嵌入向量
- OpenAIEmbeddings 示例
from langchain_openai import OpenAIEmbeddings from langchain_core.pydantic_v1 import SecretStr import os from dotenv import load_dotenv # 加载环境变量 load_dotenv() # 初始化百炼大模型text-embedding-v4 embeddings = OpenAIEmbeddings( model="text-embedding-v4", api_key=SecretStr(os.getenv("DASHSCOPE_API_KEY") or ""), base_url="https://dashscope.aliyuncs.com/api/v1/services/embeddings/text-embedding-v4" ) # 示例文本 texts = [ "这是一个示例文本。", "这是另一个示例文本,用于生成嵌入向量。" ] # 生成嵌入向量 try: embedding_vectors = embeddings.embed_documents(texts) print(f"成功生成 {len(embedding_vectors)} 个嵌入向量,每个向量维度为 {len(embedding_vectors[0])}") except Exception as e: print(f"生成嵌入向量时出错: {e}") # 为单个文本生成嵌入向量 single_text = "这是单个文本示例。" try: single_embedding = embeddings.embed_query(single_text) print(f"单个文本嵌入向量维度: {len(single_embedding)}") except Exception as e: print(f"生成单个文本嵌入向量时出错: {e}")
向量数据库
通过向量距离进行搜索匹配
- FAISS 向量数据库示例
import os import faiss import numpy as np from dotenv import load_dotenv from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import FAISS from langchain_core.documents import Document # 加载环境变量 load_dotenv() # 初始化DashScope嵌入模型 embeddings = DashScopeEmbeddings( model="text-embedding-v4", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) # 创建示例文档 documents = [ Document(page_content="风急天高猿啸哀,渚清沙白鸟飞回。"), Document(page_content="无边落木萧萧下,不尽长江滚滚来。"), Document(page_content="万里悲秋常作客,百年多病独登台。"), Document(page_content="艰难苦恨繁霜鬓,潦倒新停浊酒杯。") ] # 创建FAISS向量数据库 try: vector_store = FAISS.from_documents( documents=documents, embedding=embeddings ) print("FAISS向量数据库创建成功") except Exception as e: print(f"创建FAISS向量数据库时出错: {e}") # 保存向量数据库到本地 try: vector_store.save_local("faiss_index") print("向量数据库已保存到本地") except Exception as e: print(f"保存向量数据库时出错: {e}") # 从本地加载向量数据库 try: loaded_vector_store = FAISS.load_local( folder_path="faiss_index", embeddings=embeddings, allow_dangerous_deserialization=True ) print("向量数据库加载成功") except Exception as e: print(f"加载向量数据库时出错: {e}") # 执行相似性搜索 query = "描述秋天景象的诗句" try: # 生成查询嵌入向量 query_embedding = embeddings.embed_query(query) # 使用FAISS进行相似性搜索 docs = loaded_vector_store.similarity_search(query, k=2) print(f"\n与'{query}'相关的文档:") for i, doc in enumerate(docs, 1): print(f"{i}. {doc.page_content}") # 也可以使用自定义嵌入向量进行搜索 docs_by_vector = loaded_vector_store.similarity_search_by_vector(query_embedding, k=2) print(f"\n通过向量搜索到的文档:") for i, doc in enumerate(docs_by_vector, 1): print(f"{i}. {doc.page_content}") except Exception as e: print(f"执行相似性搜索时出错: {e}") # 获取向量数据库的FAISS索引对象,可用于更底层的操作 try: faiss_index = loaded_vector_store.index print(f"\nFAISS索引信息:") print(f"索引类型: {type(faiss_index)}") print(f"向量维度: {faiss_index.d}") print(f"向量数量: {faiss_index.ntotal}") except Exception as e: print(f"获取FAISS索引信息时出错: {e}")
自动化RAG对话链
使用自带记忆的索引增强生成对话链
- create_history_aware_retriever 示例
from langchain.chains import create_history_aware_retriever, create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.messages import HumanMessage, AIMessage from langchain_community.chat_models import ChatTongyi from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings from langchain_core.output_parsers import StrOutputParser import os # 初始化通义千问模型和嵌入 llm = ChatTongyi( model_name="qwen-plus", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) embeddings = DashScopeEmbeddings( model="text-embedding-v1", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) # 创建模拟文档和向量存储 texts = [ "LangChain是一个用于开发由语言模型驱动的应用程序的框架。", "它允许将不同的组件链接在一起以构建强大的应用程序。", "create_history_aware_retriever是一个创建历史感知检索器的函数。" ] vectorstore = FAISS.from_texts(texts, embedding=embeddings) retriever = vectorstore.as_retriever() # 创建历史感知检索器 # 该函数接受聊天历史和最新的用户问题,并生成一个考虑历史上下文的独立问题[1] contextualize_q_system_prompt = ( "给定聊天历史和最新的用户问题,该问题可能引用了聊天历史中的上下文," "请重新组织一个独立的问题,使其能够在没有聊天历史的情况下理解。" "不要回答问题,只需在需要时重新组织它,否则按原样返回。" ) contextualize_q_prompt = ChatPromptTemplate.from_messages([ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ]) history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt ) # 创建问答链 system_prompt = ( "你是一个问答任务的助手。使用以下检索到的上下文来回答问题。" "如果你不知道答案,就说你不知道。最多使用三句话,保持答案简洁。" "\n\n" "{context}" ) qa_prompt = ChatPromptTemplate.from_messages([ ("system", system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ]) question_answer_chain = create_stuff_documents_chain(llm, qa_prompt) # 组合检索链 rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain) # 运行示例 chat_history = [] input_question = "这个函数的作用是什么?" result = rag_chain.invoke({ "input": input_question, "chat_history": chat_history }) # 更新聊天历史 chat_history.extend([ HumanMessage(content=input_question), AIMessage(content=result["answer"]) ]) print("Answer:", result["answer"])
不同类型的嵌入向量
示例
from langchain.chains import create_history_aware_retriever, create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate from langchain_core.messages import HumanMessage, AIMessage from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_core.output_parsers import StrOutputParser from langchain_community.chat_models import ChatTongyi from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings from pydantic import SecretStr import os from dotenv import load_dotenv # 加载环境变量 load_dotenv() # 初始化通义千问模型和嵌入 llm = ChatTongyi( model="qwen-max", api_key=SecretStr(os.getenv("DASHSCOPE_API_KEY") or "") ) embeddings = DashScopeEmbeddings( model="text-embedding-v4", dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") ) # 加载现有的FAISS向量数据库 vectorstore = FAISS.load_local( "code/db/watermelon_book_faiss", embeddings, allow_dangerous_deserialization=True ) retriever = vectorstore.as_retriever() # 创建历史感知检索器 contextualize_q_system_prompt = ( "给定聊天历史和最新的用户问题,该问题可能引用了聊天历史中的上下文," "请重新组织一个独立的问题,使其能够在没有聊天历史的情况下理解。" "不要回答问题,只需在需要时重新组织它,否则按原样返回。" ) contextualize_q_prompt = ChatPromptTemplate.from_messages([ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ]) history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt ) # 1. Stuff方法 - 直接将所有文档传递给LLM stuff_system_prompt = ( "你是一个问答任务的助手。使用以下检索到的上下文来回答问题。" "如果你不知道答案,就说你不知道。最多使用三句话,保持答案简洁。" "\n\n" "{context}" ) stuff_qa_prompt = ChatPromptTemplate.from_messages([ ("system", stuff_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ]) stuff_chain = create_stuff_documents_chain(llm, stuff_qa_prompt) # 2. Map-Reduce方法 - 将文档分块处理然后汇总 # Map步骤提示词 map_template = """以下是一些文档片段: {docs} 请根据这些文档回答以下问题: {question} 答案:""" map_prompt = PromptTemplate.from_template(map_template) # Reduce步骤提示词 reduce_template = """以下是一组文档摘要: {docs} 请根据这些摘要回答原始问题: {question} 最终答案:""" reduce_prompt = PromptTemplate.from_template(reduce_template) # 创建Map-Reduce链(使用LCEL) def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs) def process_documents_map_reduce(input_dict): """处理Map-Reduce逻辑""" question = input_dict["input"] docs = input_dict["context"] # Map阶段:为每个文档生成摘要 map_chain = map_prompt | llm | StrOutputParser() summaries = [] for doc in docs: summary = map_chain.invoke({ "docs": doc.page_content, "question": question }) summaries.append(summary) # Reduce阶段:整合所有摘要 reduce_chain = reduce_prompt | llm | StrOutputParser() final_answer = reduce_chain.invoke({ "docs": "\n\n".join(summaries), "question": question }) return final_answer map_reduce_chain = RunnableLambda(process_documents_map_reduce) # 3. Refine方法 - 迭代式优化答案 def refine_documents(input_dict): """Refine方法实现""" question = input_dict["input"] docs = input_dict["context"] # 初始答案 initial_answer = llm.invoke(question).content # 迭代优化 refine_prompt_template = PromptTemplate.from_template( "原始问题: {question}\n已提供的答案: {existing_answer}\n" "现在你有机会通过以下更多上下文来改进答案(仅在需要时)。\n" "------------\n{context_str}\n------------\n" "根据新的上下文,改进原始答案。如果你不能改进答案,只需返回原始答案。" ) current_answer = initial_answer for doc in docs: refine_chain = refine_prompt_template | llm | StrOutputParser() current_answer = refine_chain.invoke({ "question": question, "existing_answer": current_answer, "context_str": doc.page_content }) return current_answer refine_chain = RunnableLambda(refine_documents) # 4. Map-Rerank方法 - 对文档进行重新排序 def map_rerank_documents(input_dict): """Map-Rerank方法实现""" question = input_dict["input"] docs = input_dict["context"] # 为每个文档生成答案并打分 rerank_prompt_template = PromptTemplate.from_template( "请根据以下文档回答问题,并为答案的相关性打分(0-100):\n" "问题: {question}\n" "文档: {context}\n" "格式化答案如下:\n" "分数: [分数]\n" "答案: [答案]" ) rerank_chain = rerank_prompt_template | llm | StrOutputParser() doc_scores = [] for doc in docs: response = rerank_chain.invoke({ "question": question, "context": doc.page_content }) # 解析响应中的分数和答案 try: lines = response.split('\n') score_line = [line for line in lines if line.startswith("分数:")][0] answer_line = [line for line in lines if line.startswith("答案:")][0] score = int(score_line.split(":")[1].strip()) answer = answer_line.split(":")[1].strip() doc_scores.append((score, answer, doc.page_content)) except: # 如果解析失败,给默认低分 doc_scores.append((0, response, doc.page_content)) # 按分数排序,返回最高分的答案 doc_scores.sort(key=lambda x: x[0], reverse=True) if doc_scores: return doc_scores[0][1] # 返回最高分的答案 else: return "无法生成答案" rerank_chain = RunnableLambda(map_rerank_documents) # 创建不同的检索链 stuff_rag_chain = create_retrieval_chain(history_aware_retriever, stuff_chain) map_reduce_rag_chain = create_retrieval_chain(history_aware_retriever, map_reduce_chain) refine_rag_chain = create_retrieval_chain(history_aware_retriever, refine_chain) rerank_rag_chain = create_retrieval_chain(history_aware_retriever, rerank_chain) # 运行示例 chat_history = [] input_question = "西瓜书的主要内容是什么?" print("=== 使用Stuff方法 ===") try: result = stuff_rag_chain.invoke({ "input": input_question, "chat_history": chat_history }) print("Answer:", result["answer"]) except Exception as e: print(f"Stuff方法出错: {e}") print("\n=== 使用Map-Reduce方法 ===") try: result = map_reduce_rag_chain.invoke({ "input": input_question, "chat_history": chat_history }) print("Answer:", result["answer"]) except Exception as e: print(f"Map-Reduce方法出错: {e}") print("\n=== 使用Refine方法 ===") try: result = refine_rag_chain.invoke({ "input": input_question, "chat_history": chat_history }) print("Answer:", result["answer"]) except Exception as e: print(f"Refine方法出错: {e}") print("\n=== 使用Map-Rerank方法 ===") try: result = rerank_rag_chain.invoke({ "input": input_question, "chat_history": chat_history }) print("Answer:", result["answer"]) except Exception as e: print(f"Map-Rerank方法出错: {e}")输出如下:
=== 使用Stuff方法 ===
Answer: 西瓜书,即《机器学习》一书,主要通过以西瓜为例来贯穿全书讲解机器学习的概念和技术。书中将宴席比作应用系统,菜肴比作所涉技术,而机器学习则好似宴席中必有的西瓜,强调了其在实际应用中的重要性和不可或缺性。具体来说,它覆盖了从基础概念到高级算法的广泛内容,适合不同层次的学习者。
=== 使用Map-Reduce方法 ===
Answer: 《西瓜书》,即周志华教授所著的《机器学习》一书,主要内容包括但不限于以下几个方面:
- 基础知识:介绍了机器学习的基本概念、学习理论等入门知识。
- 监督学习:深入探讨了多种监督学习算法,如线性模型、决策树、支持向量机(SVM)、贝叶斯分类器等。
- 无监督学习:涵盖了聚类分析、降维技术等内容。
- 半监督学习及强化学习:介绍了一些半监督学习的方法以及强化学习的基础知识。
- 神经网络与深度学习:虽然不是本书的重点,但也简要介绍了人工神经网络和深度学习的一些基本原理。
此外,《西瓜书》还特别强调了算法背后的数学原理及其实际应用,通过大量的实例帮助读者理解如何将理论应用于实践中。书中经常使用“西瓜”作为贯穿全书的例子来解释复杂的概念和技术,使得读者能够更容易理解和掌握机器学习的相关理论与实践方法。这本书不仅介绍了机器学习的基础知识和技术细节,也强调了其在当今科技领域的重要性及其广泛应用前景。因此,《西瓜书》是一本适合高等院校计算机科学与技术相关专业本科生或研究生使用的教材,同时也非常适合对机器学习感兴趣的读者自学。
=== 使用Refine方法 ===
Answer: 根据新提供的上下文信息,主要是关于《机器学习》一书(俗称“西瓜书”)的出版信息,并没有直接涉及到书的具体内容。因此,对于《西瓜书》的主要内容描述,我们依然保持之前的解释。不过,我们可以稍微调整答案,使其更加完整和准确。
总之,《西瓜书》,即周志华教授所著的《机器学习》,是一本全面而深入地介绍了机器学习领域的经典教材。本书不仅涵盖了广泛的主题,包括但不限于监督学习、无监督学习、半监督学习等,还特别强调了理论与实践相结合的重要性。例如,在书中可能会使用类似“西瓜数据集”的案例来说明如何从给定的数据中提取有用的模式和规则,比如通过分析根蒂和脐部特征来判断是否为好瓜这样的具体规则。这种教学方法有助于读者更直观地理解抽象的机器学习原理及其实际应用。
此外,本书由清华大学出版社于2016年出版,ISBN编号为978-7-302-42328-7。该书在编写过程中得到了许多学生、同事及学术界朋友的支持与帮助,在此特别感谢他们的贡献。对于想要进一步探索机器学习或相关技术的同学来说,除了阅读《西瓜书》之外,还可以寻找如上述提到的免费资源库中提供的其他优质资料。通过结合多种学习材料,能够更有效地掌握知识并应用到实践中去。希望每位学习者都能找到适合自己的学习路径,在机器学习这条道路上越走越远。
这样改进后的版本不仅保留了原答案的核心信息,而且增加了书籍的出版信息,使得答案更加完整。同时,继续鼓励读者利用额外的学习资源来加深他们对机器学习的理解。
=== 使用Map-Rerank方法 ===
Answer: 根据提供的文档内容,它并没有直接说明《西瓜书》的主要内容是什么。文档中提到的“西瓜”是作为一个比喻来使用的,用来形容机器学习在应用系统中的必要性和普及性。因此,根据这份文档,我们无法得知《西瓜书》具体涵盖了哪些方面的知识或技术。需要指出的是,《西瓜书》通常指的是周志华教授编著的《机器学习》一书,在该书中作者使用了“西瓜”作为贯穿全书的例子来解释复杂的机器学习概念和技术。但具体的章节内容、涵盖的主题等信息并未在此段落中给出。
四种类型的区别如下:
特性 stuffmap-reducerefinemap-rerank定义 将所有输入文档合并为一个连续的文本,然后传递给语言模型进行处理。 将输入文档拆分为多个部分,分别处理后再合并结果。 逐步细化和优化摘要,通过多次迭代改进输出质量。 通过重新排序和优化文档顺序来提高摘要效果。 适用场景 适用于较小的文本集合,不需要复杂的处理。 适用于大规模文本集合,需要并行处理。 适用于需要高质量、细致摘要的场景。 适用于需要优化文档顺序以提高摘要效果的场景。 处理方式 直接将所有文档合并后输入模型。 分阶段处理:首先对每个文档进行处理(map),然后将结果合并(reduce)。 分阶段处理:首先生成初步摘要,然后逐步细化和优化。 分阶段处理:首先对文档进行排序和重新排列,然后生成摘要。 优点 简单易用,适合快速处理。 可扩展性强,适合大规模数据。 输出质量高,适合需要精细控制的场景。 提高了文档的相关性和顺序,有助于生成更准确的摘要。 缺点 对于大规模文本可能效率较低。 需要更多的计算资源和时间。 处理时间较长,可能不适合实时应用。 需要额外的排序和优化步骤,增加了复杂性。